CoPa
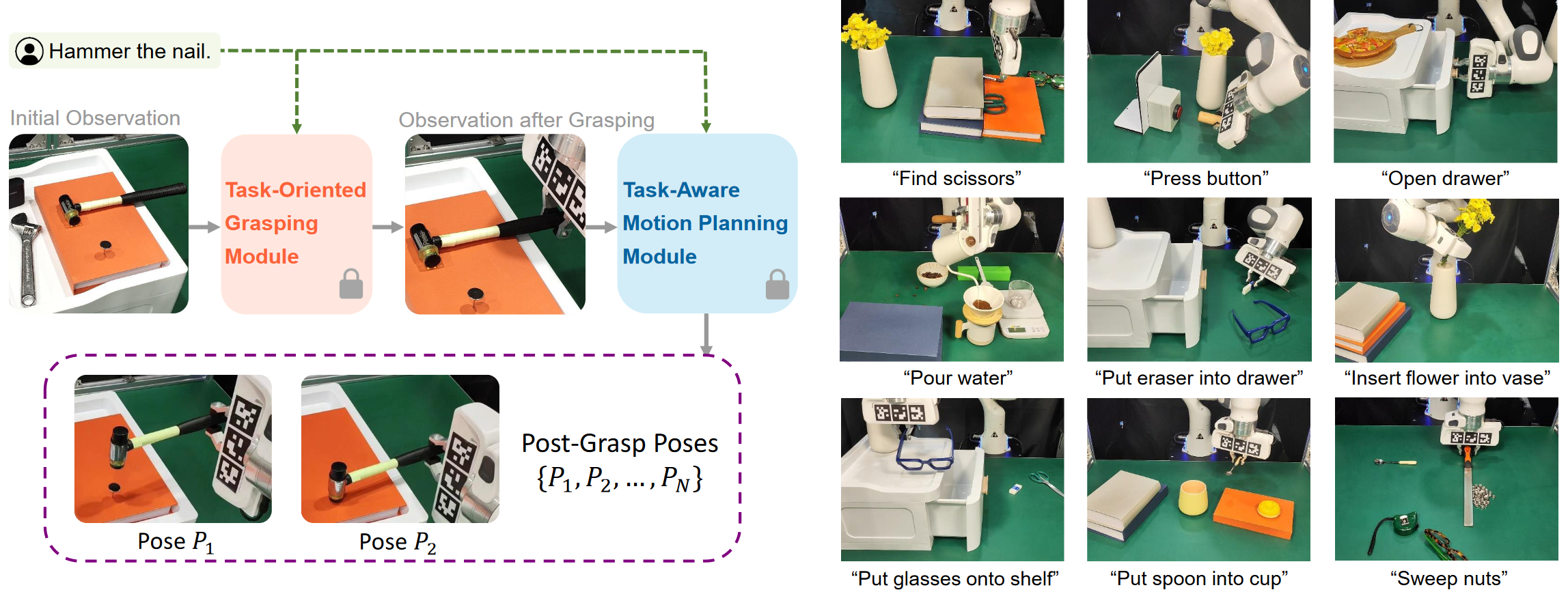
Left Our pipeline. Given an instruction and scene observation, CoPa first generates a grasp pose through Task-Oriented Grasping Module . Subsequently, a Task-Aware Motion Planning Module is utilized to obtain post-grasp poses. Right. Examples of real-world experiments. Boasting a fine-grained physical understanding of scenes, CoPa can generalize to open-world scenarios, handling open-set instructions and objects with minimal prompt engineering and without the need for additional training.
Grounding Module
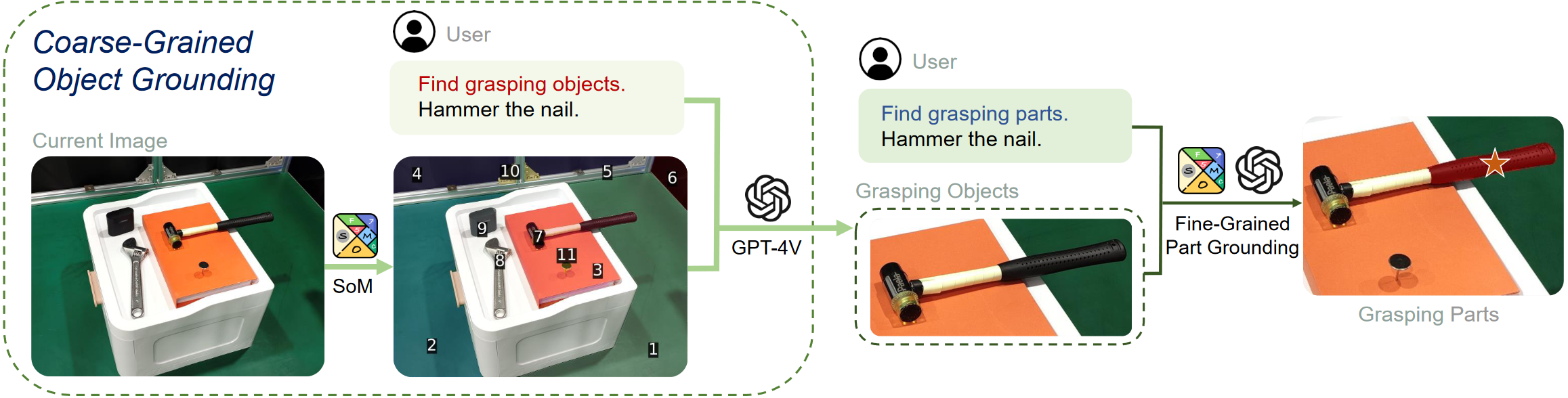
This module is utilized to identify the grasping part for task-oriented grasping or task-relevant parts for task-aware motion planning. The grounding process is divided into two stages: coarse-grained object grounding and fine-grained part grounding. Specifically, we first segment and label objects within the scene using SoM. Then, in conjunction with the instruction, we employ GPT-4V to select the grasping/task-relevant objects. Finally, similar fine-grained part grounding is applied to locate the specific grasping/task-relevant parts.
Task-Oriented Grasping Module
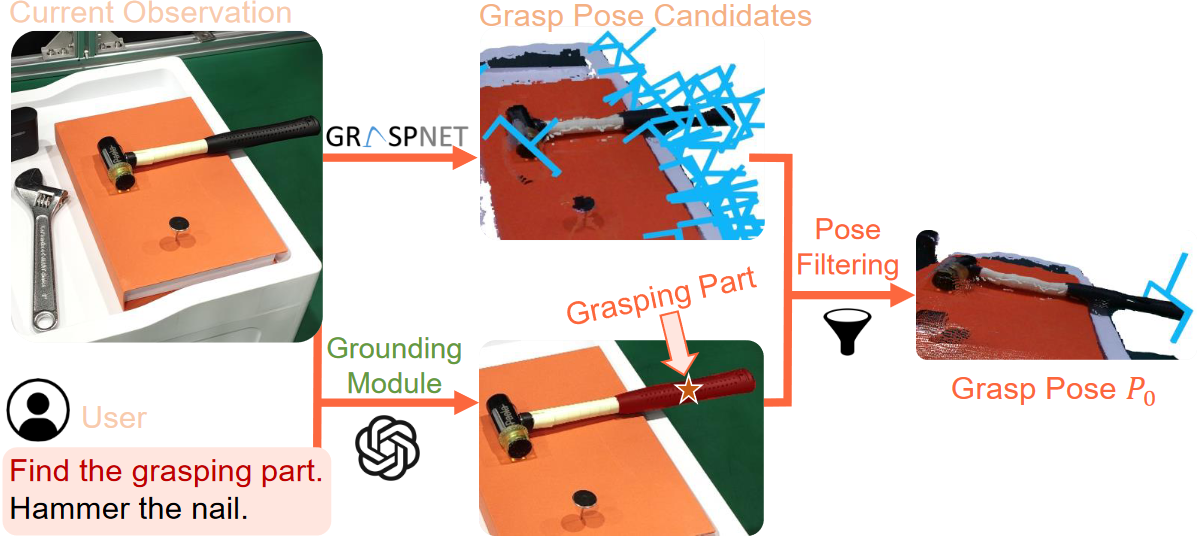
This module is employed to generate grasp poses. Initially, grasp pose candidates are generated from the scene point cloud using GraspNet. Concurrently, given the instruction and the scene image, the grasping part is identified by a grounding module. Ultimately, the final grasp pose is selected by filtering candidates based on the grasping part mask and GraspNet scores.
Task-Aware Motion Planning Module
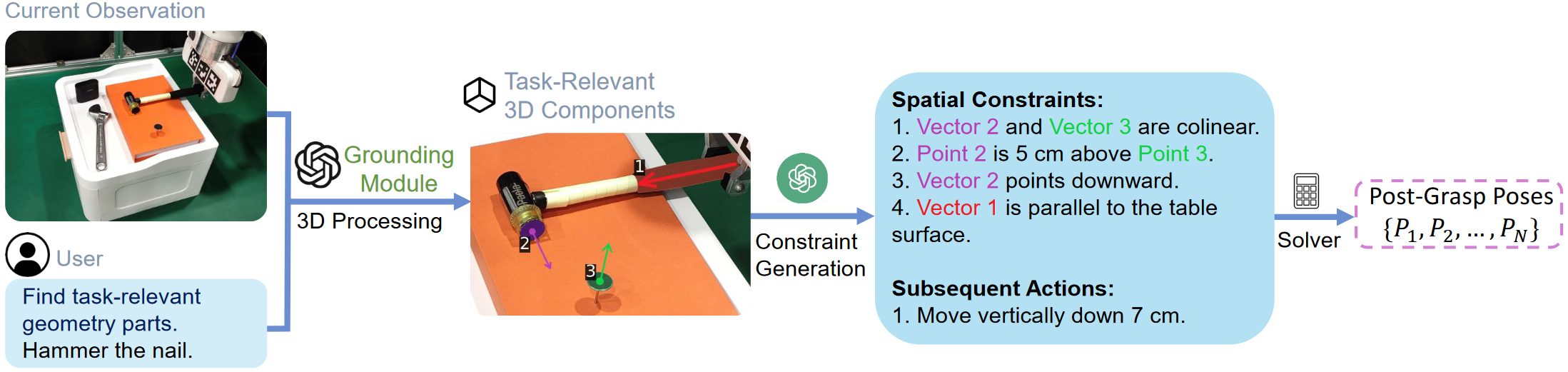
This module is used to obtain a series of post-grasp poses. Given the instruction and the current observation, we first employ a grounding module to identify task-relevant parts within the scene. Subsequently, these parts are modeled in 3D, and are then projected and annotated onto the scene image. Following this, VLMs are utilized to generate spatial constraints for these parts. Finally, a solver is applied to calculate the post-grasp poses based on these constraints.
Visualization of Spatial Constraints
Visualization of spatial constraints & post-grasp end-effector trajectory
Integration with High-Level Planning
We demonstrate the seamless integration with ViLa to accomplish long-horizon tasks. The high-level planner generates a sequence of sub-goals, which are then executed by CoPa. The results show that CoPa can be easily integrated with existing high-level planning algorithms to accomplish complex, long-horizon tasks.
ViLa:
- “Scoop coffee beans”
- “Pour beans into coffee machine”
- “Turn on coffee machine”
- “Put funnel onto carafe”
- “Pour powder into funnel”
- “Pour water to funnel”
ViLa:
- “Put flowers into vase”
- “Right fallen bottle”
- “Place fork and knife”
- “Pour wine”